| Test Coverage | ||
|---|---|---|
 | Part LXV. gcov Test Coverage Support |  |
Name
CYGPKG_GCOV
— eCos Support for the gcov test coverage
tool
Description
The GNU gcov tool provides test coverage support. After a test run it can be used to find code that was never actually executed. The testing conditions can then be adjusted for another test run to ensure that all the code really has been tested. The tool can also be used to find out how often each line of code was executed. That information can help application developers to determine where cpu time is being spent, and optimization effort can be focussed on critical parts of the code.
A typical fragment of gcov output looks something like this:
80002: 60: for (Run_Index = 1; Run_Index <= Number_Of_Runs; ++Run_Index)
-: 61: {
-: 62:
80000: 63: Proc_5();
80000: 64: while (Int_1_Loc < Int_2_Loc) /* loop body executed once */
-: 65: {
80000: 66: Int_3_Loc = 5 * Int_1_Loc - Int_2_Loc;
80000: 67: Proc_7 (Int_1_Loc, Int_2_Loc, &Int_3_Loc);
80000: 68: Int_1_Loc += 1;
-: 69: } /* while */
240000: 70: for (Ch_Index = 'A'; Ch_Index <= Ch_2_Glob; ++Ch_Index)
-: 71: /* loop body executed twice */
-: 72: {
160000: 73: if (Enum_Loc == Func_1 (Ch_Index, 'C'))
-: 74: /* then, not executed */
-: 75: {
######: 76: Proc_6 (Ident_1, &Enum_Loc);
######: 77: strcpy (Str_2_Loc, "DHRYSTONE PROGRAM, 3'RD STRING");
######: 78: Int_2_Loc = Run_Index;
######: 79: Int_Glob = Run_Index;
-: 80: }
-: 81: }
-: 82: …
-: 83: }
Each line show the execution count and line number. An execution count
of -: means that there is no executable code at
that line. In this example the main loop is executed 80000 times. The
body of the inner for loop is executed more often,
but the if condition never triggers so four lines
of code have not been tested.
The gcov tool works in conjunction with the gcc compiler. Application
code should be built with two additional compiler flags
-fprofile-arcs and -ftest-coverage.
The first option causes the compiler to generate additional code which
counts the number of times each basic block is executed. The second
option results in additional files with .gcno
suffixes which allow gcov to map these basic blocks onto lines of
source code. Older versions of the compiler used to generate files
with .bb and .bbg suffixes
instead.
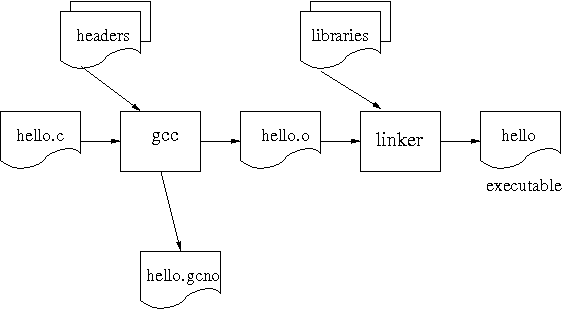
The resulting executable can be run on the target hardware as usual.
The basic block counting will initialize automatically and the counts
will accumulate. If gcov is used for native development rather than
for embedded targets then these counts will be written out to
.gcda data files automatically when the program
exits (older versions of the compiler used to generate files with
.da suffixes). A typical embedded target will not
have access to the host file system so a different approach must be
used. The counts can be extracted from the target using either a gdb
macro or by a tftp transfer, giving a single
ecosgcov.out file with counts for the entire
application. This file should then be processed with the ecosxda
script to give count files for each application source file.

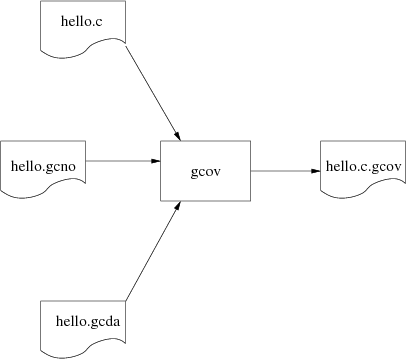
It is now possible to run gcov on each source file. The exact format of the various files varies with the compiler version so it is important to use the version of gcov that comes with the compiler.
$ m68k-elf-gcov dhrystone.c 89.25% of 214 source lines executed in file dhrystone.c Creating dhrystone.c.gcov. #
gcov will read in the basic block counts from the generated
.gcda file. These basic blocks are mapped onto
the source code using the information in the
.gcno files.
gcov provides various options, for example it can output summaries for each function. Full details of the available functionality can be found in the gcov section of the gcc documentation.
Building Applications for Test Coverage
To perform application test coverage the gcov package
CYGPKG_GCOV must first be added to the eCos
configuration. On the command line this can be achieved using:
$ ecosconfig add gcov $ ecosconfig tree $ make
Alternatively the same steps can be performed using the graphical configuration tool. The package only has two configuration options related to tftp transfers, described below.
In addition application code should be compiled with two additional
options, -fprofile-arcs and
-ftest-coverage. The first option causes the compiler
to insert additional code for basic block counting, plus an
initialization call to __gcov_init_func() which
is provided by the eCos gcov package. The second option results in
additional .gcno output files which gcov will
need later. The target-side memory needed to store the basic block
counts is allocated statically.
When code is compiled with optimization the compiler may rearrange
some of the code, if that leads to better performance. Sometimes this
causes the gcov output to be rather confusing. Compiling with
-O0, thus disabling optimization, can help.
Extracting the Data
The basic block counts must be extracted from the target and saved to
a file ecosgcov.out on the host. This package
provides two ways of doing this: a gdb macro or tftp transfers. Using
tftp is faster but requires a TCP/IP stack on the target. It also
consumes some additional target-side resources, including an extra
tftp daemon thread and its stack. The gdb macro can be used even when
the eCos configuration does not include a TCP/IP stack. However it is
much slower, typically taking several minutes to retrieve all the
counts for a non-trivial application.
The gdb macro is called gcov_dump, and can be
found in the file gcov.gdb in the host subdirectory of this package, and
in the ECOS_INSTALL_DIR/etc
(gdb) source <ECOS_INSTALL_DIR>/etc/gcov.gdb
(gdb) gcov_dump
This macro can be used any time after the application has initialized,
and will store the counts accumulated so far to the file
ecosgcov.out in the current directory. The counts
are not reset.
If the configuration includes a TCP/IP stack then the data can be
extracted using tftp instead. There are two relevant configuration
options. CYGPKG_GCOV_TFTPD controls whether or not
tftp is supported. It is enabled by default if the configuration
includes a TCP/IP stack, but can be disabled to save target-side
resources. CYGNUM_GCOV_TFTPD_PORT controls the UDP
port which will be used. This port cannot be shared with other tftp
daemons. If neither application code nor any other package (for
example the gprof profiling package) provides a tftp service then
the default port can be used. Otherwise it will be necessary to assign
unique ports to each daemon.
Using tftp requires some additional code in the application. Specifically the daemon cannot be started until the network is up and running, and that usually happens at the behest of application code rather than automatically. The following code fragment illustrates what is required:
#include <pkgconf/system.h>
#include <network.h>
#ifdef CYGPKG_GCOV
# include <pkgconf/gcov.h>
# include <cyg/profile/gcov.h>
#endif
…
int
main(int argc, char** argv)
{
…
init_all_network_interfaces();
#ifdef CYGPKG_GCOV_TFTPD
gcov_start_tftpd();
#endif
…
}The data can then be retrieved using a standard tftp client. There are a number of such clients available with very different interfaces, but a typical session might look something like this:
$ tftp tftp> connect 10.1.1.134 tftp> binary tftp> get ecosgcov.out Received 138740 bytes in 1.7 seconds tftp> quit
The address 10.1.1.134 should be replaced with the
target's IP address.
ecosxda
gcov expects separate .gcda files for each
application source file compiled with -fprofile-arcs.
However it would be inconvenient to extract each
.gcda file via tftp or a gdb macro. Instead the
data is first written to a single file
ecosgcov.out. The ecosxda utility script should
then be used to process ecosgcov.out and generate
the .gcda files.
The ecosxda script can be found in the host subdirectory of this package. Since
it is a simple Tcl script it does not need to be built or installed.
If desired it can be copied to a suitable location on the user's
PATH. Alternatively the subdirectory contains
suitable configure and
Makefile.in files, allowing the script to be
installed automatically as part of the generic eCos host-side build
system. The toplevel file README.host contains
more information about this.
Typically ecosxda will be invoked with no arguments.
$ ecosxda
It will read in an ecosgcov.out file from the
current directory and output or update the .gcda
files appropriate for the application. If a given
.gcda file already exists then by default ecosxda
will read it in and merge the old and new counts, rather than write a
new set. This allows data from several test runs to accumulate, giving
more comprehensive test coverage. Merging the counts is only possible
if the source file has not been recompiled, otherwise the old counts
will be discarded to avoid contaminated results.
ecosxda takes a number of command line options.
- -h, --help
- Provide brief usage information.
- -V, --version
- Display the version of the ecosxda script being used.
- -v, --verbose
- Provide additional diagnostic output. Repeated uses increase the level of verbosity.
- -n, --no-output
-
Do not actually create or modify any
.gcdafiles. Typically this is used to find out whether any files would be replaced rather than merged, and it can also be used to validate theecosgcov.outfile. - -r, --replace
-
This forces ecosxda to ignore any existing counts in the
.gcdafiles, rather than try to merge the existing and new counts. Typically it is used to discard the results from previous test runs.
In addition it is possible to specify the file containing the new
counts, instead of the default ecosgcov.out. This
may prove useful if several sets of results are extracted to different
files during a single test run, to determine what code gets run at
various stages. For example:
$ ecosxda -r stage2.out
Directories and eCos Test Coverage
In a simple build environment the source code, the
.gcno files generated by the compiler, and the
.gcda files output by ecosxda, will all reside in
the same directory. That makes it easy for gcov to find the various
files it needs. gcov will also generate its .gcov
files in the same directory.
In more complicated build environments the source code may be kept completely separate from the build tree. eCos itself provides an example of this: the source code is held in a clean component repository, and builds happen in separate build trees. To use gcov in such an environment it is necessary to understand what files will be created where:
-
The compiler will output the
.gcnofile in the same directory as the object file. For an eCos build tree this will be below the version directory of each package. For example, if the kernel source filesync/mutex.cxxis built with-ftest-coveragethen thekernel/current/src/syncsubdirectory in the build tree will contain themutex.gcnofiles. -
The
.gcdafiles will end up in the same directory as the.gcnofiles. The compiler puts the full path name in each object file, and this path is copied into theecosgcov.outfile and used by ecosxda. It is assumed thatecosgcov.outwill be processed on the same machine that was used to compile the code. -
When gcov is invoked it can be given a full pathname for the source
file. By default it assumes that the other files will be in the
current directory, but a
-ocommand line option can be used to override this. -
gcov will output its
.gcovfiles in the current directory.
To perform test coverage of eCos itself, in addition to or instead of
the application, it is necessary to rebuild eCos with the appropriate
flags. This involves changing the configuration option
CYGBLD_GLOBAL_CFLAGS to include
-ftest-coverage and -fprofile-arcs,
then performing a clean and a full make. The basic block counts can be
extracted and processed with ecosxda as before, and the
.gcno and .gcda files will
all end up in the build tree. This test coverage data can then be
processed in the build tree using, for example:
$ cd <build> $ cd kernel/<version> $ m68k-elf-gcov -o . <repo>/kernel/<version>/sync/mutex.cxx … 58.50% of 147 source lines executed in file <repo>/kernel/current/src/sync/mutex.cxx Creating mutex.cxx.gcov.
Where <build> is the location of the build tree and <repo> is the location of the eCos component repository.
Additional Target-side Functions
The eCos gcov package provides a small number of additional
target-side functions. Prototypes for these are provided in the header
file <cyg/profile/gcov.h>.
…
int
main(int argc, char** argv)
{
…
init_all_network_interfaces();
#ifdef CYGPKG_GCOV_TFTPD
gcov_start_tftpd();
#endif
…
}
If the eCos configuration includes a TCP/IP stack and if a target-side
tftp daemon will be used to extract the data from the target to the
host then application code should call
gcov_start_tftpd once the network is up. This
cannot be done automatically by the gcov package itself since that
package has no simple way of detecting when the network is ready.
extern void gcov_reset(void);
This function can be used to reset all basic block counts. If the application operates in a number of distinct stages then it may be useful to get coverage data for each stage, rather than a single set of results for the whole test run. It can also be used to get test coverage for a specific sequence of external inputs.
64-bit arithmetic is used for the basic block counts. Hence it should not be necessary to perform occasional resets to avoid counters overflowing.
To operate properly gcov_reset needs to disable
interrupts for a while, so it should not be used in situations which
require hard real-time performance.
extern void gcov_dump(void);
This is a utility routine which outputs some of the basic block
information via diag_printf calls. It is intended
primarily to help with debugging the gcov code itself.
In addition the <cyg/profile/gcov.h> header
exports the data type gcov_module and a
variable gcov_head which acts as the head of a
linked list of gcov_module structures.
This allows application code to access and manipulate the basic block
data directly, if desired.
| |  | |
| Part LXV. gcov Test Coverage Support |  | Part LXVI. CRC Algorithms |
| 2025-10-02 | eCosPro Non-Commercial Public License |