| Chapter 2. Package Organization | ||
|---|---|---|
 |  | |
Chapter 2. Package Organization
Table of Contents
For a package to be usable in the eCos component framework it must conform to certain rules imposed by that framework. Packages must be distributed in a form that is understood by the component repository administration tool. There must be a top-level CDL script which describes the package to the component framework. There are certain limitations related to how a package gets built, so that the package can still be used in a variety of host environments. In addition to these rules, the component framework provides a number of guidelines. Packages do not have to conform to the guidelines, but sticking to them can simplify certain operations.
This chapter deals with the general organization of a package, for example how to distinguish between private and exported header files. Chapter 3, The CDL Language describes the CDL language. Chapter 4, The Build Process details the build process.
2.1. Packages and the Component Repository
All eCos installations include a component repository. This is a directory structure for all installed packages. The component framework comes with an administration tool that allows new packages or new versions of a package to be installed, old packages to be removed, and so on. The component repository includes a simple database, maintained by the administration tool, which contains details of the various packages.
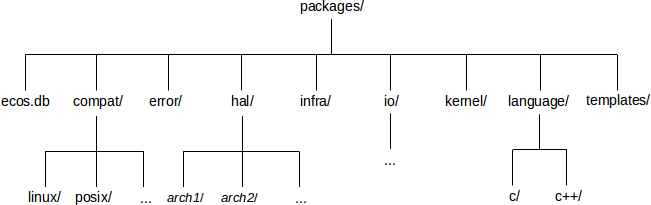
Each package has its own little directory hierarchy within the
component repository. Keeping several packages in a single directory
is illegal. The error, infra and kernel packages all live at the
top-level of the repository. For other types of packages there are
some pre-defined directories: compat is used for compatibility
packages, which implement other interfaces such as µITRON or POSIX
using native eCos calls; hal
is used for packages that port eCos to different architectures or
platforms, and this directory is further organized on a
per-architecture basis; io is
intended for device drivers; language is used for language support
libraries, for example the C library. There are no strict rules
defining where new packages should get installed. Obviously if an
existing top-level directory such as compat is applicable then the new package
should go in there. If a new category is desirable then it is possible
to create a new sub-directory in the component repository. For
example, an organization planning to release a number of eCos
packages may want them all to appear below a sub-directory
corresponding to the organization's name — in the hope that
the name will not change too often. It is possible to add new packages
directly to the top-level of the component repository, but this should
be avoided.
The ecos.db file holds the component repository
database and is managed by the administration tool. The various
configuration tools read in this file when they start-up to obtain
information about the various packages that have been installed. When
developing a new package it is necessary to add some information to
the file, as described in Section 3.8, “Updating the ecos.db database”. The
templates directory holds
various configuration templates.
![[Note]](pix/note.png) | Note |
|---|---|
Earlier releases of eCos came with two separate files,
|
![[Caution]](pix/caution.png) | Caution |
|---|---|
The current ecos.db database does not yet provide all of the information needed by the component framework. Its format is subject to change in future releases, and the file may be replaced completely if necessary. There are a number of other likely future developments related to the component repository and the database. The way targets are described is subject to change. Sometimes it is desirable for component writers to do their initial development in a directory outside the component repository, but there is no specific support in the framework for that yet. |
2.2. Package Versioning
Below each package directory there can be one or more version sub-directories, named after the versions. This is a requirement of the component framework: it must be possible for users to install multiple versions of a package and select which one to use for any given application. This has a number of advantages to users: most importantly it allows a single component repository to be shared between multiple users and multiple projects, as required; also it facilitates experiments, for example it is relatively easy to try out the latest version of some package and see if it makes any difference. There is a potential disadvantage in terms of disk space. However since eCos packages generally consist of source code intended for small embedded systems, and given typical modern disk sizes, keeping a number of different versions of a package installed will usually be acceptable. The administration tool can be used to remove versions that are no longer required.
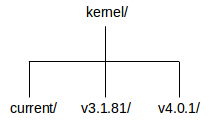
The version current is special. Typically it
corresponds to the very latest version of the sources, obtained by
anonymous CVS. These sources may change frequently, unlike full
releases which do not change (or only when patches are produced).
Component writers may also want to work on the
current version.
All other subdirectories of a package correspond to specific releases of that package. The component framework allows users to select the particular version of a package they want to use, but by default the most recent one will be used. This requires some rules for ordering version numbers, a difficult task because of the wide variety of ways in which versions can be identified.
The version
currentis always considered to be the most recent version.If the first character of both strings are either
vorV, these are skipped because it makes little sense to enforce case sensitivity here. Potentially this could result in ambiguity if there are two version directoriesV1.0andv1.0, but this will match the confusion experienced by any users of such a package. However if two subsequent releases are calledV1.0andv1.1, e.g. because of a minor mix-up when making the distribution file, then the case difference is ignored.Next the two version strings are compared one character at a time. If both strings are currently at a digit then a string to number conversion takes place, and the resulting numbers are compared. For example
v10is a more recent release thanv2. If the two numbers are the same then processing continues, so forv2bandv2cthe version comparison code would move on tobandc.The characters dot
., hyphen-and underscore_are treated as equivalent separators, so if one release goes out asv1_1and the next goes out asv1.2the separator has no effect.If neither string has yet terminated but the characters are different, ASCII comparison is used. For example
V1.1bis more recent thanv1.1alpha.If one version string terminates before the other, the current character determines which is the more recent. If the other string is currently at a separator character, for example
v1.3.1andv1.3, then the former is assumed to be a minor release and hence more recent than the latter. If the other string is not at a separator character, for examplev1.3beta, then it is treated as an experimental version of thev1.3release and hence older.There is no special processing of dates, so with two versions
ss-20000316andss-20001111the numerical values20001111and20000316determine the result: larger values are more recent. It is suggested that the full year be used in such cases rather than a shorthand like00, to avoid Y2100 problems.There is no limit on how many levels of versioning are used, so there could in theory be a
v3.1.4.1.5.9.2.7release of a package. However this is unlikely to be of benefit to typical users of a package.
The version comparison rules of the component framework may not be suitable for every version numbering scheme in existence, but they should cope with many common cases.
| Caution |
|---|---|
There are some issues still to be resolved before it is possible to
combine the |
2.3. Package Contents and Layout
A typical package contains the following:
Some number of source files which will end up in a library. The application code will be linked with this library to produce an executable. Some source files may serve other purposes, for example to provide a linker script.
Exported header files which define the interface provided by the package.
On-line documentation, for example reference pages for each exported function.
Some number of test cases, shipped in source format, allowing users to check that the package is working as expected on their particular hardware and in their specific configuration.
One or more CDL scripts describing the package to the configuration system.
It is also conventional to have a per-package
ChangeLog file used to keep track of changes to
that package. This is especially valuable to end users of the package
who may not have convenient access to the source code control system
used to manage the master copy of the package, and hence cannot find
out easily what has changed. Often it can be very useful to the main
developers as well.
Any given packages need not contain all of these. It is compulsory to have at least one CDL script describing the package, otherwise the component framework would be unable to process it. Some packages may not have any source code: it is possible to have a package that merely defines a common interface which can then be implemented by several other packages, especially in the context of device drivers; however it is still common to have some code in such packages to avoid replicating shareable code in all of the implementation packages. Similarly it is possible to have a package with no exported header files, just source code that implements an existing interface: for example an ethernet device driver might just implement a standard interface and not provide any additional functionality. Packages do not need to come with any on-line documentation, although this may affect how many people will want to use the package. Much the same applies to per-package test cases.
The component framework has a recommended per-package directory layout which splits the package contents on a functional basis:
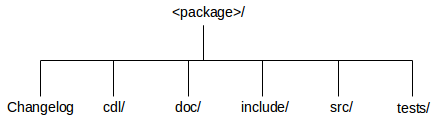
For example, if a package has an include sub-directory then the component
framework will assume that all header files in and below that
directory are exported header files and will do the right thing at
build time. Similarly if there is doc property indicating the
location of on-line documentation then the component framework will
first look in the doc
sub-directory.
This directory layout is just a guideline, it is not enforced by the
component framework. For simple packages it often makes more sense to
have all of the files in just one directory. For example a package
could just contain the files hello.cxx,
hello.h, hello.html and
hello.cdl. By default
hello.h will be treated as an exported header
file, although this can be overridden with the include_files property. Assuming
there is a doc property referring to hello.html
and there is no doc
sub-directory then the tools will search for this file relative to the
package's top-level and everything will just work. Much the same
applies to hello.cxx and
hello.cdl.
![[Tip]](pix/tip.png) | Tip |
|---|---|
Older versions of the eCos build system only supported packages that
followed the directory structure exactly. Hence certain core packages
such as |
2.3.1. Outline of the Build Process
The full build process is described in Chapter 4, The Build Process, but a summary is appropriate here. A build involves three directory structures:
The component repository. This is where all the package source code is held, along with CDL scripts, documentation, and so on. For build purposes a component repository is read-only. Application developers will only modify the component repository when installing or removing packages, via the administration tool. Component writers will typically work on just one package in the component repository.
The build tree. Each configuration has its own build tree, which can be regenerated at any time using the configuration's
ecos.eccsavefile. The build tree contains only intermediate files, primarily object files. Once a build is complete the build tree contains no information that is useful for application development and can be wiped, although this would slow down any rebuilds following changes to the configuration.The install tree. This is populated during a build, and contains all the files relevant to application development. There will be a
libsub-directory which typically containslibtarget.a, a linker script, start-up code, and so on. There will also be anincludesub-directory containing all the header files exported by the various packages. There will also be ainclude/pkgconfsub-directory containing various configuration header files with#define'sfor the options. Typically the install tree is created within the build tree, but this is not a requirement.
The build process involves the following steps:
Given a configuration, the component framework is responsible for creating all the directories in the build and install trees. If these trees already exist then the component framework is responsible for any clean-ups that may be necessary, for example if a package has been removed then all related files should be expunged from the build and install trees. The configuration header files will be generated at this time. Depending on the host environment, the component framework will also generate makefiles or some other way of building the various packages. Every time the configuration is modified this step needs to be repeated, to ensure that all option consequences take effect. Care is taken that this will not result in unnecessary rebuilds.
Note At present this step needs to be invoked manually. In a future version the generated makefile may if desired perform this step automatically, using a dependency on the
ecos.eccsavefile.The first step in an actual build is to make sure that the install tree contains all exported header files. All compilations will use the install tree's
includedirectory as one of the places to search for header files.All source files relevant to the current configuration get compiled. This involves a set of compiler flags initialized on a per-target basis, with each package being able to modify these flags, and with the ability for the user to override the flags as well. Care has to be taken here to avoid inappropriate target-dependencies in packages that are intended to be portable. The component framework has built-in knowledge of how to handle C, C++ and assembler source files — other languages may be added in future, as and when necessary. The compile property is used to list the files that should get compiled. All object files end up in the build tree.
Once all the object files have been built they are collected into a library, typically
libtarget.a, which can then be linked with application code. The library is generated in the install tree.The component framework provides support for custom build steps, using the make_object and make properties. The results of these custom build steps can either be object files that should end up in a library, or other files such as a linker script. It is possible to control the order in which these custom build steps take place, for example it is possible to run a particular build step before any of the compilations happen.
2.3.2. Configurable Source Code
All packages should be totally portable to all target hardware (with the obvious exceptions of HAL and device driver packages). They should also be totally bug-free, require the absolute minimum amount of code and data space, be so efficient that cpu time usage is negligible, and provide lots of configuration options so that application developers have full control over the behavior. The configuration options are optional only if a package can meet the requirements of every potential application without any overheads. It is not the purpose of this guide to explain how to achieve all of these requirements.
The eCos component framework does have some important implications for the source code: compiler flag dependencies; package interfaces vs. implementations; and how configuration options affect source code.
2.3.2.1. Compiler Flag Dependencies
Wherever possible component writers should avoid dependencies on particular compiler flags. Any such dependencies are likely to impact portability. For example, if one package needs to be built in big-endian mode and another package needs to be built in little-endian mode then usually it will not be possible for application developers to use both packages at the same time; in addition the application developer is no longer given a choice in the matter. It is far better for the package source code to adapt the endianness at compile-time, or possibly at run-time although that will involve code-size overheads.
| Note |
|---|---|
A related issue is that the current support for handling compiler flags in the component framework is still limited and incapable of handling flags at a very fine-grain. The support is likely to be enhanced in future versions of the framework, but there are non-trivial problems to be resolved. |
2.3.2.2. Package Interfaces and Implementations
The component framework provides encapsulation at the package level. A
package A has no way of accessing the
implementation details of another package B at
compile-time. In particular, if there is a private header file
somewhere in a package's src
sub-directory then this header file is completely invisible to other
packages. Any attempts to cheat by using relative pathnames beginning
with ../.. are generally doomed
to failure because of the presence of package version directories.
There are two ways in which one package can affect another: by means
of the exported header files, which define a public interface; or via
the CDL scripts.
This encapsulation is a deliberate aspect of the overall eCos component framework design. In most cases it does not cause any problems for component writers. In some cases enforcing a clean separation between interface and implementation details can improve the code. Also it reduces problems when a package gets upgraded: component writers are free to do pretty much anything on the implementation side, including renaming every single source file; care has to be taken only with the exported header files and with the CDL data, because those have the potential of impacting other packages. Application code is similarly unable to access package implementation details, only the exported interface.
Very occasionally the inability of one package to see implementation
details of another does cause problems. One example occurs in HAL
packages, where it may be desirable for the architectural, variant and
platform HAL's to share some information that should not be visible to
other packages or to application code. This may be addressed in the
future by introducing the concept of friend
packages, just as a C++ class can have friend
functions and classes which are allowed special access to a class
internals. It is not yet clear whether such cases are sufficiently
frequent to warrant introducing such a facility.
2.3.2.3. Source Code and Configuration Options
Configurability usually involves source code that needs to implement different behavior depending on the settings of configuration options. It is possible to write packages where the only consequence associated with various configuration options is to control what gets built, but this approach is limited and does not allow for fine-grained configurability. There are three main ways in which options could affect source code at build time:
The component code can be passed through a suitable preprocessor, either an existing one such as m4 or a new one specially designed with configurability in mind. The original sources would reside in the component repository and the processed sources would reside in the build tree. These processed sources can then be compiled in the usual way.
This approach has two main advantages. First, it is independent from the programming language used to code the components, provided reasonable precautions are taken to avoid syntax clashes between preprocessor statements and actual code. This would make it easier in future to support languages other than C and C++. Second, configurable code can make use of advanced preprocessing facilities such as loops and recursion. The disadvantage is that component writers would have to learn about a new preprocessor and embed appropriate directives in the code. This makes it much more difficult to turn existing code into components, and it involves extra training costs for the component writers.
Compiler optimizations can be used to elide code that should not be present, for example:
… if (CYGHWR_NUMBER_UARTS > 0) { … } …If the compiler knows that
CYGHWR_NUMBER_UARTSis the constant number 0 then it is a trivial operation to get rid of the unnecessary code. The component framework still has to define this symbol in a way that is acceptable to the compiler, typically by using aconstvariable or a preprocessor symbol. In some respects this is a clean approach to configurability, but it has limitations. It cannot be used in the declarations of data structures or classes, nor does it provide control over entire functions. In addition it may not be immediately obvious that this code is affected by configuration options, which may make it more difficult to understand.Existing language preprocessors can be used. In the case of C or C++ this would be the standard C preprocessor, and configurable code would contain a number of
#ifdefand#ifstatements.#if (CYGHWR_NUMBER_UARTS > 0) … #endif
This approach has the big advantage that the C preprocessor is a technology that is both well-understood and widely used. There are also disadvantages: it is not directly applicable to components written in other languages such as Java (although it is possible to use the C preprocessor as a stand-alone program); the preprocessing facilities are rather limited, for example there is no looping facility; and some people consider the technology to be ugly. Of course it may be possible to get around the second objection by extending the preprocessor that is used by gcc and g++.
The current component framework generates configuration header files
with C preprocessor #define's for each option
(typically, there various properties which can be used to control
this). It is up to component writers to decide whether to use
preprocessor #ifdef statements or language
constructs such as if. At present there is no
support for languages which do not involve the C preprocessor,
although such support can be added in future when the need arises.
2.3.3. Exported Header Files
A package's exported header files should specify the interface provided by that package, and avoid any implementation details. However there may be performance or other reasons why implementation details occasionally need to be present in the exported headers.
| Note |
|---|---|
Not all programming languages have the concept of a header file. In some cases the component framework would need extensions to support packages written in such languages. |
Configurability has a number of effects on the way exported header
files should be written. There may be configuration options which
affect the interface of a package, not just the implementation. It is
necessary to worry about nested #include's and how
this affects package and application builds. A special case of this
relates to whether or not exported header files should
#include configuration headers. These configuration
headers are exported, but should only be #include'd
when necessary.
2.3.3.1. Configurable Functionality
Many configuration options affect only the implementation of a package, not the interface. However some options will affect the interface as well, which means that the options have to be tested in the exported header files. Some implementation choices, for example whether or not a particular function should be inlined, also need to be tested in the header file because of language limitations.
Consider a configuration option
CYGFUN_KERNEL_MUTEX_TIMEDLOCK which controls
whether or not a function cyg_mutex_timedlock is
provided. The exported kernel header file cyg/kernel/kapi.h could contain the
following:
#include <pkgconf/kernel.h> … #ifdef CYGFUN_KERNEL_MUTEX_TIMEDLOCK extern bool cyg_mutex_timedlock(cyg_mutex_t*); #endif
This is a correct header file, in that it defines the exact interface
provided by the package at all times. However is has a number of
implications. First, the header file is now dependent on pkgconf/kernel.h, so any changes to
kernel configuration options will cause cyg/kernel/kapi.h to be out of date, and
any source files that use the kernel interface will need rebuilding.
This may affect sources in the kernel package, in other packages, and
in application source code. Second, if the application makes use of
this function somewhere but the application developer has
misconfigured the system and disabled this functionality anyway then
there will now be a compile-time error when building the application.
Note that other packages should not be affected, since they should
impose appropriate constraints on
CYGFUN_KERNEL_MUTEX_TIMEDLOCK if they use that
functionality (although of course some dependencies like this may get
missed by component developers).
An alternative approach would be:
extern bool cyg_mutex_timedlock(cyg_mutex_t*);
Effectively the header file is now lying about the functionality provided by the package. The first result is that there is no longer a dependency on the kernel configuration header. The second result is that an application file using the timed-lock function will now compile, but the application will fail to link. At this stage the application developer still has to intervene, change the configuration, and rebuild the system. However no application recompilations are necessary, just a relink.
Theoretically it would be possible for a tool to analyze linker errors and suggest possible configuration changes that would resolve the problem, reducing the burden on the application developer. No such tool is planned in the short term.
It is up to component writers to decide which of these two approaches
should be preferred. Note that it is not always possible to avoid
#include'ing a configuration header file in an
exported one, for example an option may affect a data structure rather
than just the presence or absence of a function. Issues like this will
vary from package to package.
2.3.3.2. Nested #include's
As a general rule, unnecessary #include's should be
avoided. A header file should #include only those
header files which are absolutely needed for it to define its
interface. Any additional #include's make it more
likely that package or application source files become dependent on
configuration header files and will get rebuilt unnecessarily when
there are minor configuration changes.
2.3.3.3. Including Configuration Headers
Exported header files should avoid #include'ing
configuration header files unless absolutely necessary, to avoid
unnecessary rebuilding of both application code and other packages
when there are minor configuration changes. A
#include is needed only when a configuration option
affects the exported interface, or when it affects some implementation
details which is controlled by the header file such as whether or not
a particular function gets inlined.
There are a couple of ways in which the problem of unnecessary
rebuilding could be addressed. The first would require more
intelligent handling of header file dependency handling by the tools
(especially the compiler) and the build system. This would require
changes to various non-eCos tools. An alternative approach would be to
support finer-grained configuration header files, for example there
could be a file pkgconf/libc/inline.h controlling which
functions should be inlined. This could be achieved by some fairly
simple extensions to the component framework, but it makes it more
difficult to get the package header files and source code correct:
a C preprocessor #ifdef directive does not
distinguish between a symbol not being defined because the option is
disabled, or the symbol not being defined because the appropriate
configuration header file has not been #include'd.
It is likely that a cross-referencing tool would have to be developed
first to catch problems like this, before the component framework
could support finer-grained configuration headers.
2.3.4. Package Documentation
On-line package documentation should be in HTML format. The component framework imposes no special limitations: component writers can decide which version of the HTML specification should be followed; they can also decide on how best to cope with the limitations of different browsers. In general it is a good idea to keep things simple.
2.3.5. Test Cases
Packages should normally come with one or more test cases. This allows application developers to verify that a given package works correctly on their particular hardware and in their particular configuration, making it slightly more likely that they will attempt to find bugs in their own code rather than automatically blaming the component writers.
At the time of writing the application developer support for building
and running test cases via the component framework is under review and
likely to change. Currently each test case should consist of a single
C or C++ source file that can be compiled with the package's set of
compiler flags and linked like any application program. Each test case
should use the testing API defined by the infrastructure. A
magically-named calculated configuration option of the form
CYGPKG_<PACKAGE-NAME>_TESTS lists the test
cases.
2.3.6. Host-side Support
On occasion it would be useful for an eCos package to be shipped with host-side support. This could take the form of an additional tool needed to build that package. It could be an application intended to communicate with the target-side package code and display monitoring information. It could be a utility needed for running the package test cases, especially in the case of device drivers. The component framework does not yet provide any such support for host-side software, and there are obvious issues related to portability to the different machines that can be used for hosts. This issue may get addressed in some future release. In some cases custom build steps can be subverted to do things on the host side rather than the target side, but this is not recommended.
2.4. Making a Package Distribution
Developers of new eCos packages are advised to distribute their packages in the form of eCos package distribution files. Packages distributed in this format may be added to existing eCos component repositories in a robust manner using the Package Administration Tool. This chapter describes the format of package distribution files and details how to prepare an eCos package for distribution in this format.
2.4.1. The eCos package distribution file format
eCos package distribution files are gzipped GNU tar archives which contain both the source code for one or more eCos packages and a data file containing package information to be added to the component repository database. The distribution files are subject to the following rules:
The data file must be named
pkgadd.dband must be located in the root of the tar archive. It must contain data in a format suitable for appending to the eCos repository database (ecos.db). Section 3.8, “Updating the ecos.db database” describes this data format. Note that a database consistency check is performed by the eCos Administration Tool whenpkgadd.dbhas been appended to the database. Any new target entries which refer to unknown packages will be removed at this stage.The package source code must be placed in one or more
<package-path>/<version>directories in the tar archive, where each <package-path> directory path is specified as the directory attribute of one of the packages entries inpkgadd.db.An optional license agreement file named
pkgadd.txtmay be placed in the root of the tar archive. It should contain text with a maximum line length of 79 characters. If this file exists, the contents will be presented to the user during installation of the package. The eCos Package Administration Tool will then prompt the user with the question"Do you accept all the terms of the preceding license agreement?". The user must respond"yes"to this prompt in order to proceed with the installation.Optional template files may be placed in one or more
templates/<template_name>directories in the tar archive. Note that such template files would be appropriate only where the packages to be distributed have a complex dependency relationship with other packages. Typically, a third party package can be simply added to an eCos configuration based on an existing core template and the provision of new templates would not be appropriate.The distribution file must be given a
.epk(not.tar.gz) file extension. The.epkfile extension serves to distinguish eCos package distributions files from generic gzipped GNU tar archives. It also discourages users from attempting to extract the package from the archive manually. The file browsing dialog of the eCos Package Administration Tool lists only those files which have a.epkextension.No other files should be present in the archive.
Files in the tar archive may use
LForCRLFline endings interchangably. The eCos Administration Tool ensures that the installed files are given the appropriate host-specific line endings.Binary files may be placed in the archive, but the distribution of object code is not recommended. All binary files must be given a
.binsuffix in addition to any file extension they may already have. For example, the GIF image filemyfile.gifmust be namedmyfile.gif.binin the archive. The.binsuffix is removed during file extraction and is used to inhibit the manipulation of line endings by the eCos Administration Tool.
2.4.2. Preparing eCos packages for distribution
Development of new eCos packages or new versions of existing eCos packages will take place in the context of an existing eCos component repository. This section details the steps involved in extracting new packages from a repository and generating a corresponding eCos package distribution file for distribution of the packages to other eCos users. The steps required are as follows:
Create a temporary directory
$PKGTMPfor manipulation of the package distribution file contents and copy the source files of the new packages into this directory, preserving the relative path to the package. In the case of a new package atmypkg/currentin the repository:$ mkdir -p $PKGTMP/mypkg $ cp -p -R $ECOS_REPOSITORY/mypkg/current $PKGTMP/mypkg
Where more than one package is to be distributed in a single package distribution file, copy each package in the above manner. Note that multiple packages distributed in a single package distribution file cannot be installed separately. Where such flexibility is required, distribution of each new package in separate package distribution files is recommended.
Copy any template files associated with the distributed packages into the temporary directory, preserving the relative path to the template. For example:
$ mkdir -p $PKGTMP/templates $ cp -p -R $ECOS_REPOSITORY/templates/mytemplate $PKGTMP/templates
Remove any files from the temporary directory hierarchy which you do not want to distribute with the packages (eg object files,
CVSdirectories).Add a
.binsuffix to the name of any binary files. For example, if the packages contains GIF image files (*.gif) for documentation purposes, such files must be renamed to *.gif.bin as follows:$ find $PKGTMP -type f -name '*.gif' -exec mv {} {}.bin ';'The
.binsuffix is removed during file extraction and is used to inhibit the manipulation of line endings by the eCos Package Administration Tool.Extract the package records for the new packages from the package database file at $ECOS_REPOSITORY/ecos.db and create a new file containing these records at
$PKGTMP/pkgadd.db(in the root of the temporary directory hierarchy). Any target records which reference the distributed packages must also be provided in pkgadd.db.Rename the version directories under
$PKGTMP(typicallycurrentduring development) to reflect the versions of the packages you are distributing. For example, version 1.0 of a package may use the version directory namev1_0:$ cd $PKGTMP/mypkg $ mv current v1_0
Section 2.2, “Package Versioning” describes the version naming conventions.
Rename any template files under
$PKGTMP(typicallycurrent.ectduring development) to reflect the version of the template you are distributing. For example, version 1.0 of a template may use the filenamev1_0.ect:$ cd $PKGTMP/templates/mytemplate $ mv current.ect v1_0.ect
It is also important to edit the contents of the template file, changing the version of each referenced package to match that of the packages you are distributing. This step will eliminate version warnings during the subsequent loading of the template.
Optionally create a licence agreement file at
$PKGTMP/pkgadd.txtcontaining the licensing terms under which you are distributing the new packages. Limit each line in this file to a maximum of 79 characters.Create a GNU tar archive of the temporary directory hierarchy. By convention, this archive would have a name of the form
<package_name>-<version>:$ cd $PKGTMP $ tar chf mypkg-1.0.tar *
Note that non-GNU version of tar may create archive files which exhibit subtle incompatibilities with GNU tar. For this reason, always use GNU tar to create the archive file. In addition, for a truly portable archive, the archive must not contain any symbolic references as not all systems support these. The -h (--dereference) flag must therefore be included when creating the archive to ensure the file the symbolic link points to is archived and not the symbolic link.
Compress the archive using gzip and give the resulting file a
.epkfile extension:$ gzip mypkg-1.0.tar $ mv mypkg-1.0.tar.gz mypkg-1.0.epk
The resulting eCos package distribution file (*.epk) is in a compressed format and may be distributed without further compression.
| | | |
| Chapter 1. Overview |  | Chapter 3. The CDL Language |
| 2025-10-02 | Open Publication License |